





The surface level complexity of feature flagging seems easy to solve. We install some code that talks back to LaunchDarkly, flip a switch, and our application “receives” that change and acts on it. It’s easy to write this off as a basic problem to solve however at the end of the day, if features aren’t being successfully delivered within your application and to your users, with high performance and perfect consistency, what sort of confidence can we have in it working at all?
How do we guarantee when your app first starts up that it receives all the correct values? In the event the connection is lost for some reason, how do we ensure they persist? How do we ensure that a user leveraging a mobile device in a remote part of Asia gets the same experience as a laptop in San Francisco? What about when it’s a million different devices? My point is, the underlying architecture that guarantees delivery resilience, scale, and performance is just as important as the delivery of the flag itself.
To that point, we talk A LOT about the strengths of our architecture at LaunchDarkly. We mention statistics like serving “20 trillion flags a day” or “deliver updates in 200ms” as proof points that support our architecture decisions. Being on the inside, I’m fortunate to have the opportunity to learn about all the pieces (one might even call them “features”) that make all of that possible, and the way those components are continuing to evolve - and share those learnings here.
Recently, we moved significant portions of our flag evaluation tooling from our core LaunchDarkly infrastructure, out to the Content Delivery Network (CDN) layer of our architecture. We refer to this as Flag Delivery at Edge, and it is currently live throughout our LaunchDarkly Flag Delivery Network. We’ll come back to that a bit later.
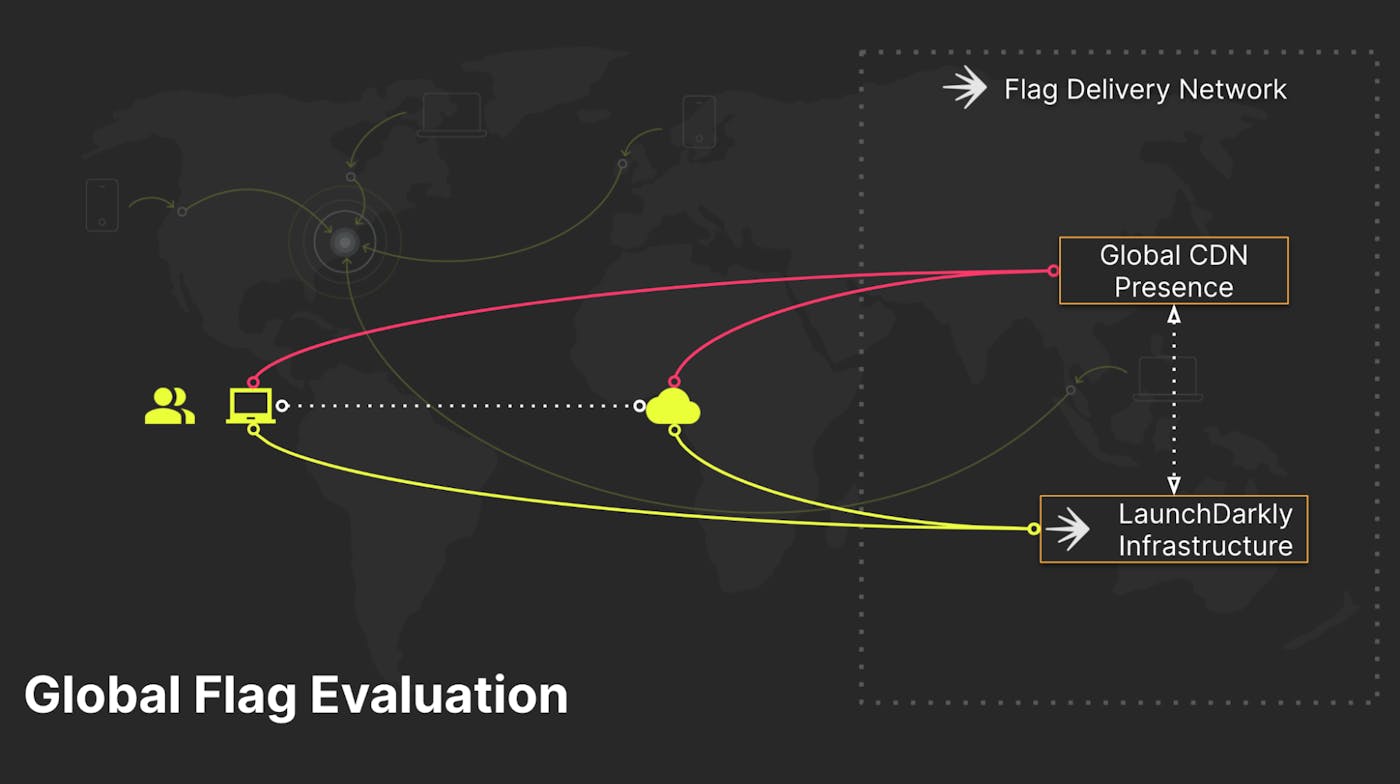
The Flag Delivery Network consists of our own LaunchDarkly infrastructure and a globally-distributed CDN. Application workloads initialize (the SDK start up process) against these CDN’s to pull their initial flag and rule payloads down to the workload endpoints (through our client/server SDKs). After that initialization completes, the workloads enter into either a polling or a streaming pattern for future flag updates; defaulting to streaming connections whenever possible.
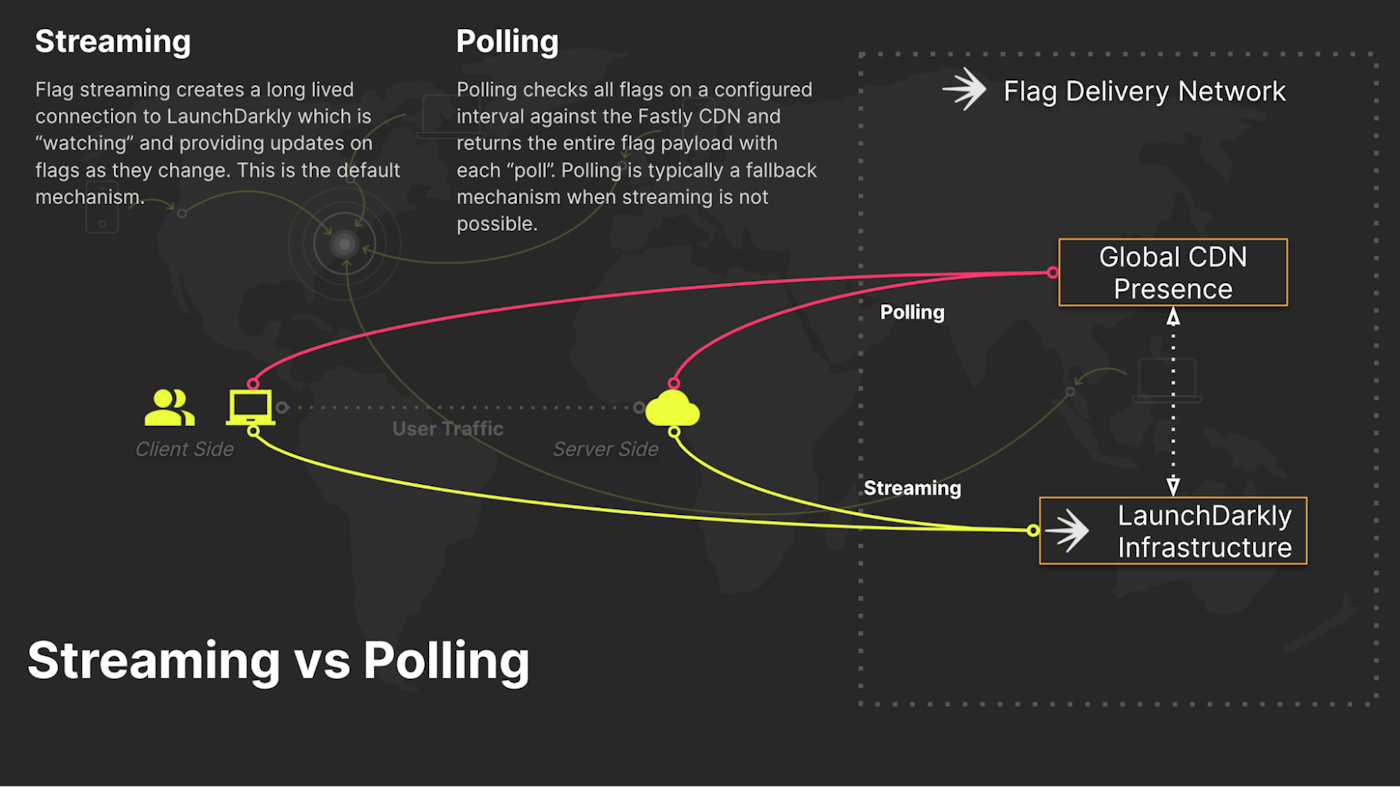
With streaming connections, the SDK receives only flag values that change after initialization. For example, if an operator disables a flag, only that single flag value will be pushed into the
stream and delivered to the application workload. In the case of polling connections, the entire flag payload is delivered at each interval. Polling connections leverage the global CDN nodes for their payload delivery. This payload is significantly larger than streamed connections, which is why we leverage streaming whenever possible.
Knowing that we had made significant optimizations already on streaming and polling scenarios, the next logical place to focus on was improving our SDK start up performance or initialization. In cases where user connections successfully had a “cache-hit” against our CDN, they would experience fantastic initialization times. However, in our most challenging connection types - remote areas and mobile devices - we noted significant cache miss percentages and as a result, much higher initialization times. For our users, this meant client connections briefly received the default flag values before the new values were loaded (most commonly visually as a flicker of the old values). On the positive side, we were still benefiting from security aspects of LaunchDarkly, but we had situations where performance suffered. And now we’re back to where we started: Flag Delivery at Edge.

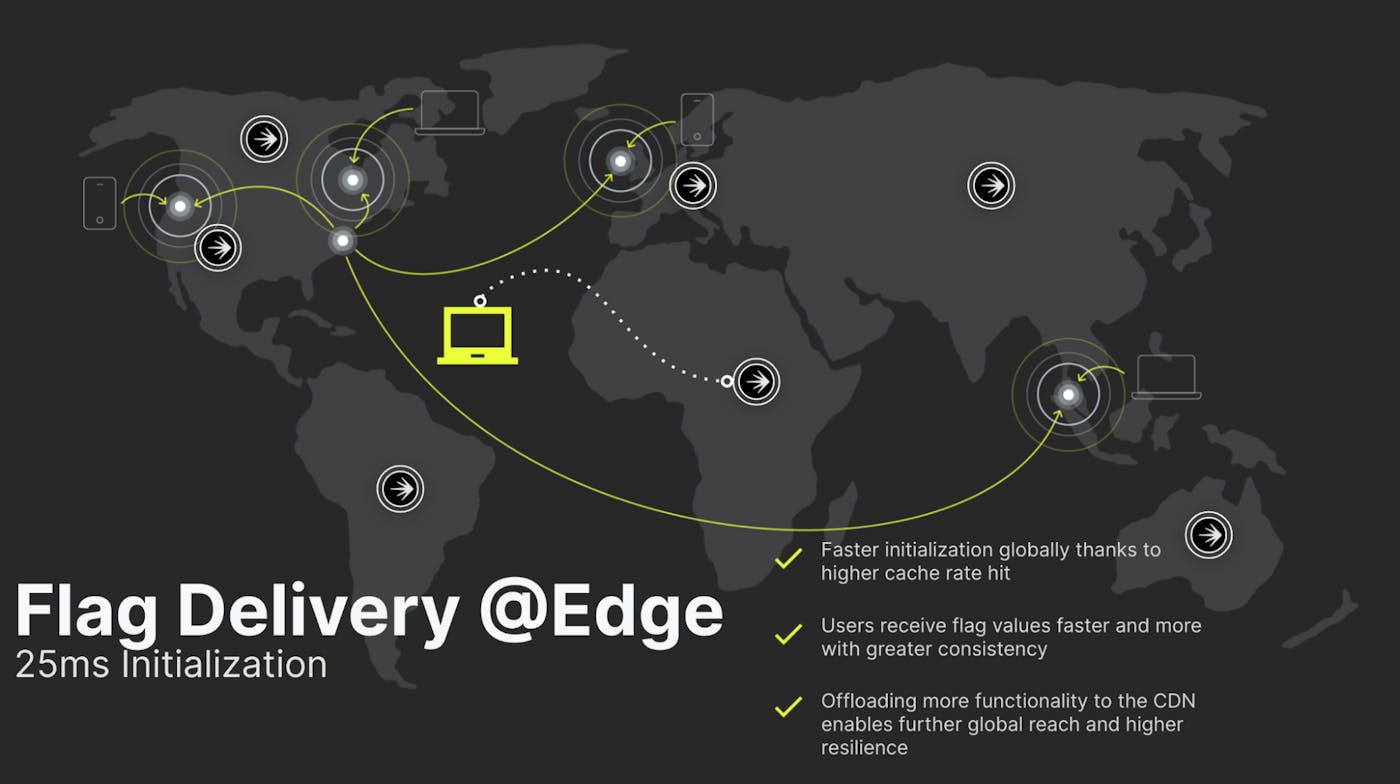
Flag Delivery at Edge takes our already extensive Flag Delivery Network and improves upon it by leveraging our CDN in a smarter and more holistic way. We’re enhancing our caching strategy by moving key services of the LaunchDarkly flag database and initialization system to the edge layer for processing. Previously these components lived within our LaunchDarkly core infrastructure, which in the case of a cache miss, would require user connections to “round-trip” all the way to the core in order to satisfy the request.
Moving these components to the edge allows us to leverage our CDN (nearly 100 points of presence around the globe) to drastically improve our performance, and raise our cache hit rate. From a “real numbers” perspective, this allowed us to reduce the client initialization time from the hundreds of milliseconds to around 25ms — even in those previously mentioned challenging connectivity scenarios. In some cases, we’ve seen a more than 10x improvement in connection speed as a result of this enhancement.
Wrapping Up
We’ve invested a lot in ensuring we have the fastest and most resilient Flag Delivery Network possible. That resilience is provided at multiple different layers: the LaunchDarkly core environment as the single source of truth, the CDN’s that cache that data, components like the relay proxy which allow users to cache locally within their own environment, and all the way down to the local default flag values in the user code.
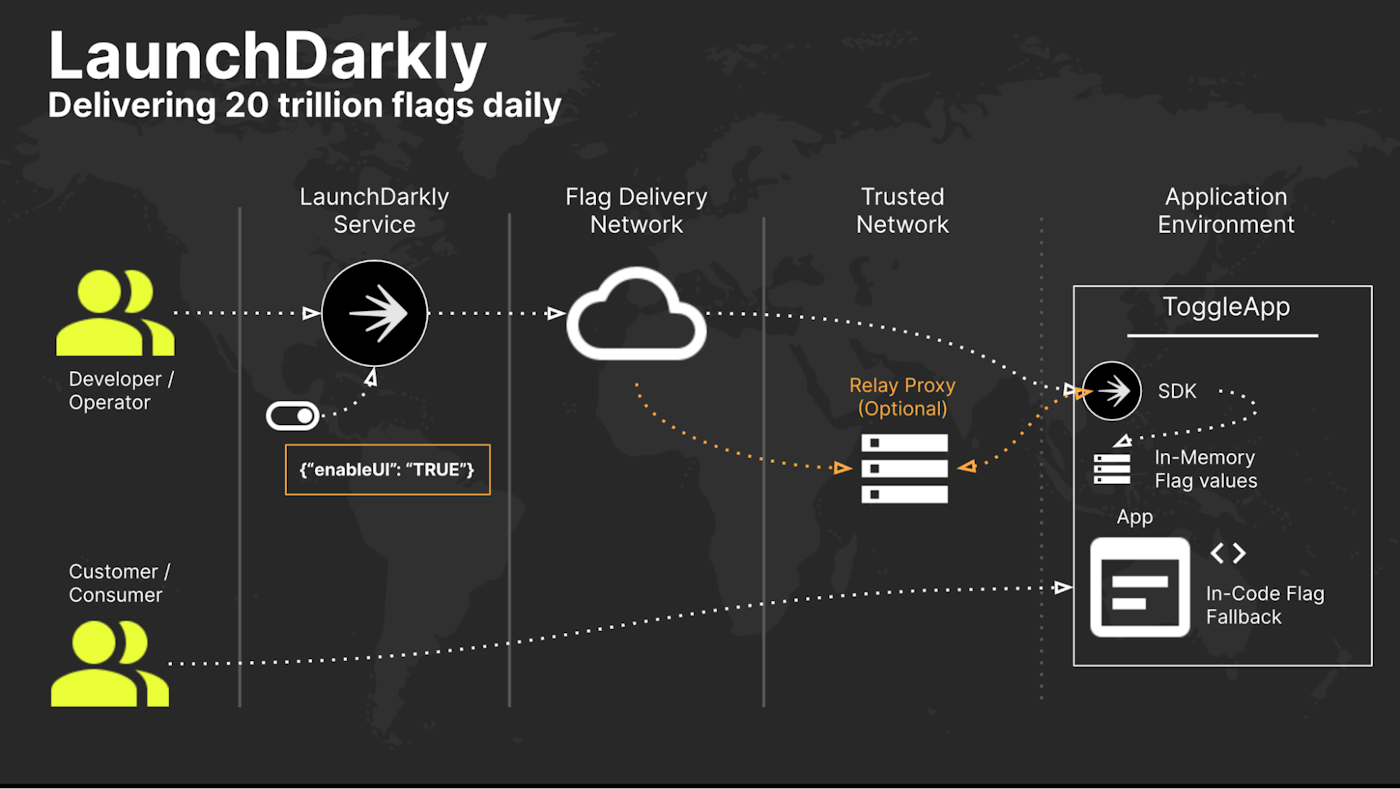
Evolving our Flag Delivery Network by implementing Flag Delivery at Edge allowed us to significantly improve performance for even some of the most challenging connection times (remote geography, mobile device, etc). It’s currently live across the entirety of our CDN. More importantly, this architecture change shows that we are continuing to look at ways to innovate and build a stronger flag network for developers and operators as we scale beyond serving 20 trillion flags daily.
Like what you read?
Get a demo