





LLMs can meaningfully increase speed and productivity in a wide range of applications. They are also nondeterministic in their output and carry the risk of hallucinations and errors that can be costly and time-consuming to rectify. The need to determine LLM capabilities for a given use case has led to a wide range of LLM evaluation techniques, the most popular of which are LLM benchmarks to rank performance in different domains.
Because simple benchmarks can be easily gamed, effective LLM evaluation goes beyond simply relying on basic benchmarks to validate that an LLM is performant, effective, and cost-efficient in a specific use case.
In this article, we will delve into LLM evaluation in detail, covering the challenges AI engineers encounter when assessing LLMs, various evaluation metrics, practical examples (with code), and best practices that teams can use to evaluate an LLM.
Summary of key LLM evaluation concepts
The table below summarizes seven important LLM evaluation concepts this article will explore in detail.
Concept | Description |
|---|---|
LLM Evaluation | The process of measuring how well a large language model performs across tasks, contexts, and safety dimensions. |
Perplexity | A metric for intrinsic evaluation that measures how surprised a model is by the actual next word in a sequence. Lower is better. |
BLEU / ROUGE / METEOR | Surface-form metrics for comparing generated text to references; used in translation, summarization, and generation tasks. |
LLM-as-a-Judge | Using a powerful LLM (like GPT-4o) to evaluate or grade the outputs of other models or tasks. |
Red teaming | A method from security and military strategy — probing a model with adversarial inputs to find vulnerabilities or unsafe behavior. |
Jailbreaking | Using clever or adversarial prompts to bypass an LLM’s built-in safety or guardrails. |
Null models | A research concept demonstrating that trivial or constant-response models can sometimes skew benchmarks, revealing flaws in tests. |
What is LLM evaluation, and why is it challenging?
Evaluating LLM models is both challenging and exciting due to their diverse applications and the significant impact they have. LLM evaluation can refer to either the LLM model or the LLM system. In LLM model evaluation, engineers assess a particular model (e.g., GPT-4o) across different tasks or domains, often without assistive components, meaning they rely on no external tools. LLM system evaluation is based on a particular setup (like a chatbot based on the LLaMa model for mental health support).
What makes it so challenging is the stochastic nature of the generated text. Three different people would get different responses to “Explain Quantum Mechanics to me as an 8-year-old,” and all three responses can be relevant. Simple statistical evaluation metrics for other tasks, such as computer vision, can’t be applied to LLM evaluation; hence, we need smarter evaluation metrics. Additionally, there is a philosophical aspect to it, as we can also have subjective interpretations of correct answers. For instance, the correct answer to “What is the right time for dinner?” depends more on the audience than the model.
Other factors to balance here include coherence, helpfulness, sensitivity to prompts, safety, and so on, and hence require more complex metrics. The lack of sufficient benchmarks—and the ease with which existing ones can be manipulated—is another major challenge.
Why do we need LLM evaluation?
LLMs are used in numerous critical applications, and there must be ways to ensure their reliability. The hallucination problem is the most common one and can have a profound impact on the business and customers (as seen in the case of Air Canada’s chatbot). With the growing focus on the ethical aspects (as seen in the EU AI Act and the US AI Bill, and California’s SB 53, among others), it becomes even more critical for our LLM-based applications to be reliable in specific ways.
Given this, two key considerations come into play.
- LLM variety. There are a large number of LLMs available for various tasks. So, a single LLM may not be fit for all use cases.
- Addressing a practical use case while satisfying constraints. It is important to find the best LLM for your use case, which also satisfies constraints such as cost, privacy, and latency.
Therefore, to find the best LLM model that satisfies these criteria, it is important to evaluate and compare different LLMs.
LLM evaluation also allows us to compare and contrast different models. A standardized evaluation method will ensure fair comparison. There can also be cases where we have an LLM fine-tuned to our data and therefore needs to be adapted to downstream tasks.
By carefully evaluating LLMs, you can find the one that best meets your needs while also understanding their strengths and limits.
Types of LLM Evaluation
LLM evaluation can be categorized as model and system evaluation. In model evaluation, engineers check a model generically (for diverse use cases).
Model evaluation
Model evaluation can be either extrinsic or intrinsic. The intrinsic evaluation aims to assess how well this model performs, using metrics such as perplexity. Extrinsic evaluation assesses how well the model performs on downstream tasks, such as a document translator or a chatbot.
Note: Teams also conduct behavioral evaluations occasionally, which assess the model’s behavior in scenarios that require safety, fairness, and robustness.
System evaluation
System evaluation determines how well a model performs for a particular use case, such as a RAG-based chatbot, and, therefore, has numerous applications in both industry and research. System evaluation doesn’t pluck a system out of nowhere and test it in isolation; instead, it uses the proper context and often a whole pipeline.
Benchmarks for model evaluation
Several benchmarks are used for evaluating LLM models. These benchmarks aren’t perfect, but are helpful in their own ways.
- MMLU (Multitask Understanding): MMLU assesses a model across a wide range of diverse tasks (57, precisely) spanning STEM, social sciences, and humanities. MMLU uses a multiple-choice format.
- GSM8K (Grade School Math Reasoning): GSM8K focuses on mathematical problems. It features more than 8500 mathematical problems for the middle school level.
- SWE-bench (Software Engineering Tasks): SWE-bench evaluates models on software engineering problems using GitHub public repositories.
- Chatbot Arena: Chatbot Arena is an open benchmark that relies on users’ voting to evaluate LLMs. Since voting is voluntary, it takes some time (often months) before an LLM gets sufficient feedback.
- TruthfulQA, ARC, HumanEval, etc.: These benchmarks evaluate the model's capability to deliver accurate results, even when faced with misleading queries, such as “Which city of Germany was chosen by Allies for nuclear strike in WW2?”, which should still result in the correct Japanese cities.
Note: To reduce human annotation costs, automatic LLM benchmarks like AlpacaEval 2.0 and MT-Bench are also available. They also have a high correlation with Chatbot Arena and provide a good tradeoff between cost and accuracy.
Benchmark limitations
“All models are wrong, but some are useful” also applies to benchmarks: we shouldn’t rely too heavily on them and recognize their limitations.
Some of the common limitations are:
Data leakage: Imagine a model that is already trained on the test dataset. LLM models use heaps of publicly available data, which can include some (or all) of these benchmarks as well.
Overfitting: The quest to fulfill a benchmark may end up having an overfitted model (particularly on that benchmark).
Language and culture bias: When using ChatGPT (or any other model) for Arabic or Persian language tasks, the results will be poorer compared to those available in English. Similarly, the use of more data from specific (usually Western) countries by the LLMs also introduces a cultural bias. For example, try asking an LLM model, “How to celebrate my upcoming birthday,” and the answer is expected to follow specific Western themes (like cakes, balloons, and candles) more often than Oriental ones.
This benchmark limitation is a pretty hot research area. Recently, a paper on “null models” was published, highlighting the limitations of some existing benchmarks and suggesting which models can perform better in these areas.
LLM evaluation metrics
For evaluation, we have surface-form and semantic metrics. Surface-form metrics include BERTScore, Perplexity, METEOR, F1, etc. It would be worthwhile to give a quick overview.
- BERTScore: A more advanced metric that uses embeddings to see if the meaning of the generated summary is similar to the reference, even if the exact words are different
- METEOR: Goes beyond simple word matching. It considers synonyms and word roots, aiming to capture how semantically similar your generated summary is to the reference.
- Perplexity: In this metric, the model tries to guess the next word in a sentence. Perplexity is a measure of how "surprised" the model is by the actual next word. A lower perplexity means the model is less surprised, indicating it finds the text very natural and fluent
- Faithfulness: LLMs often generate confident but wrong information. The Faithfulness metric determines whether (and to what extent) the response remains true to the original context and/or factual knowledge.
- Toxicity/bias: LLMs live and die by the sword. Their expressibility also means that there’s always a probability of generating toxic/biased content. This measure takes care of that.
Semantic metrics utilize embeddings to assess the semantic similarity between the target and generated text. They use measures like BERTScore, Cosine similarity, or MoverScore. Also frequently utilized evaluation metrics are Perplexity, Exact Match, and pass@k, each tailored for particular tasks.
Additionally, modern AI evaluation includes task completion to measure whether systems fulfill user requests, answer relevance to assess how well responses address the original question, hallucination detection to identify false information, correctness for factual accuracy verification, tool selection evaluation in multi-agent environments, and contextual relevance to ensure appropriate use of given context.
LLM evaluation methods
Let’s take a look at three modern LLM evaluation methods AI engineers can use.
LLM-as-a-Judge
One of the most common evaluation methods is to use an LLM itself as a judge, such as using GPT-4 to assess another model (including system evaluation). While it’s easier, it does have its own limitations..
Its methodology is simple: we provide the LLM with a prompt that contains the results generated by both models and then compare them. It can return comments on their outputs, scores, or both. For example, we can input this prompt into the LLM:
Question: How to boil an egg?
Answer A: Place the egg in boiling water for 8 minutes.
Answer B: Put the egg in cold water, bring to a boil, then simmer for 10 minutes.
Judge's instruction: Pick the answer that is clearer, safer, and more helpful for a novice cook.
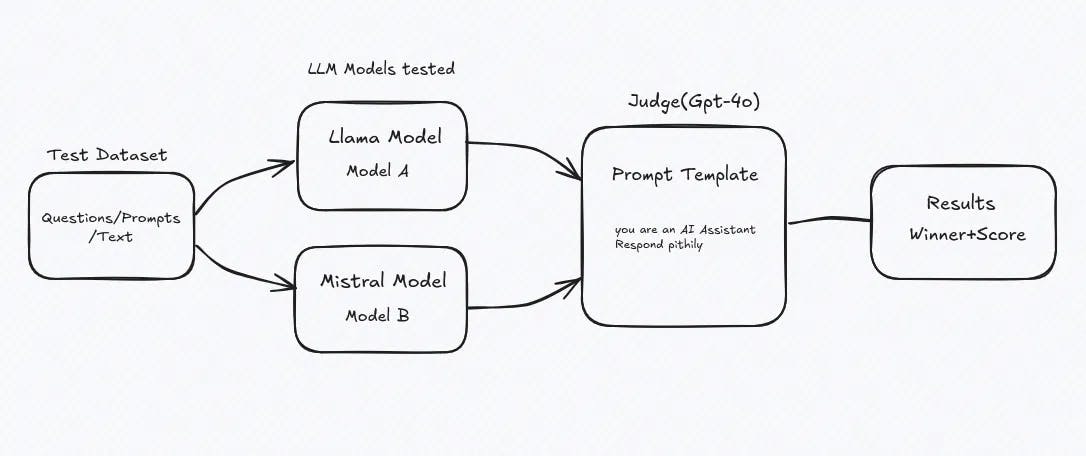
So, using LLMs as judges is a smart way to assess LLMs, none other than LLMs themselves.
Hybrid evaluation
Hybrid evaluation is based on the idea that LLMs using LLMs alone to judge an LLM is not enough. A more effective approach is to employ hybrid evaluation, which combines the use of both LLMs and humans as judges.
Red teaming and robustness testing
LLMs are very effective and improving a lot at the rate of knots, but there are some safety challenges, like:
- Generating toxic and abusive content.
- Leaking private data if it's memorized (be careful with ChatGPT, as it memorizes all your conversations now).
- Giving dangerous instructions (like how to make a bomb).

Still, it's possible to bypass the safety instructions by jailbreaking (i.e., using some clever prompts to bypass restrictions). Therefore, robustness testing, such as red teaming, is essential. Red teaming is commonly used in cybersecurity, where we simulate system vulnerabilities through adversarial attacks. We can also use this technique for LLM evaluation, specifically to check the model’s robustness in terms of safety.
Note: Red teaming derives its name from the military strategy/practices where a “red team” is introduced as an adversary to check the system’s defense.
Leading AI companies like OpenAI, Anthropic, and DeepMind have their own red teams (for internal use).
A practical LLM evaluation example
Enough of theory, now let's code a bit. We will use the text summarization task on the “CNN/DailyMail” dataset with LLM-as-a-Judge to evaluate which model performs better. We will begin by importing the required libraries and setting up the environment.
import os
import time
import torch
import nltk
import json
import evaluate
from datasets import load_dataset
from transformers import pipeline, AutoTokenizer, AutoModelForSeq2SeqLM
from openai import OpenAI
from bert_score import score as bert_score
from dotenv import load_dotenv
# Setup OpenAI API & NLTK
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY_HERE"
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
#Download required NLTK data for tokenization
nltk.download("punkt", quiet=True)
# Load dataset (20 examples for comparison)
dataset = load_dataset("cnn_dailymail", "3.0.0", split="test[:20]")
articles = [item["article"] for item in dataset]
references = [item["highlights"] for item in dataset]We will evaluate two powerful LLM models, Google’s Gemini and Facebook’s LlaMa, to assess their performance in summarization tasks.
Gemini_model = pipeline("text-generation", model="google/gemma-2b",device=0 if torch.cuda.is_available() else -1)
print("Gemini model loaded successfully")
meta_Llama3 = pipeline("text-generation", model="meta-llama/Meta-Llama-3-8B",device=0 if torch.cuda.is_available() else -1)
print("meta Llama 3 loaded successfully")Define LLM-as-a-Judge function
Now we will define the LLM-as-a-Judge function “gpt-compare_summaries()”, which utilizes GPT-4 to compare the two models.
def gpt_compare_summaries(article,Google_Gemini_model, meta_Llama3_model):
"""Use GPT-4o to judge which summary is better"""
system_prompt = """You are a highly efficient assistant, who evaluates and selects the best large language model (LLMs) based
on the quality of their responses to a given instruction. This process will be used to create a leaderboard reflecting the
most accurate and human-preferred answers."""
user_prompt = f"""
I require a leaderboard for various large language models. I'll provide you with prompts given to these models and their
corresponding outputs. Your task is to assess these responses, and select the model that produces the best output from a human
perspective.
## Instruction
\\"\\"\\"{article}\\"\\"\\"
{{ "instruction": "Summarize the given news article clearly, concisely, and completely." }}
## Model Outputs
[
{{
"model_identifier": "Google_Gemini",
"output": \\"\\"\\"{Google_Gemini_model}\\"\\"\\"
}},
{{
"model_identifier": "meta_Llama3",
"output": \\"\\"\\"{meta_Llama3_model}\\"\\"\\"
}}
]
## Evaluation Criteria
You must assess each summary using the following five criteria:
1. Style - Is the writing engaging and well-structured?
2. Language Quality - Is it grammatically correct and fluent?
3. Coherence - Does the summary flow logically?
4. Accuracy - Are the facts correct with respect to the article?
5. Faithfulness - Does the summary cover all key points from the article without adding false information?
## Task
Evaluate the models based on the quality and relevance of their outputs, and select the model that generated the best output.
Answer by providing the model identifier of the best model. Use only one of these exactly (no quotes, spaces, or new lines):
Google_Gemini or meta_Llama3
## Best Model Identifier
""".strip()
try:
if not Google_Gemini_model or not meta_Llama3_model:
print("Warning: Empty summary provided to GPT-4o comparison")
return "tie"
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=3
)
return response.choices[0].message.content.strip()
except Exception as e:
print(f"Error with GPT-4o API: {e}")
return "tie"Compile and evaluate results
After defining the LLM judge, we will set the evaluation settings. Outputs will be 30-600 characters long, while counters for both Gemini and Llama are initialized to zero.
#Summary Generation Configuration
MODEL_CONFIG = {
"max_new_tokens": 600,
"temperature": 0.0,
"top_p": 1.0,
"repetition_penalty": 1.0,
"return_full_text": False
}
# Initialize counters for LLM-as-judge results
Gemini_wins = 0
llama3_wins = 0
ties = 0
def generate_summary(model, article, max_article_length=1024):
"""Generate a summary for the given article"""
try:
truncated_article = article[:max_article_length]
if not truncated_article.strip():
print("Warning: Empty article input")
return ""
result = model(truncated_article, **MODEL_CONFIG)
if isinstance(result, list) and len(result) > 0:
if isinstance(result[0], dict):
first = result[0]
summary = first.get("summary_text") or first.get("generated_text", "")
elif isinstance(result[0], str):
summary = result[0]
else:
raise ValueError(f"Unexpected output format in list: {type(result[0])}")
else:
raise ValueError(f"Unexpected or empty output from model: {result}")
print(f"DEBUG: Extracted summary: '{summary[:100]}...'")
if torch.cuda.is_available():
torch.cuda.empty_cache()
return summary.strip()
except Exception as e:
print(f"Error generating summary: {e}")
return ""Now we will pass the samples (from the CNN/Dailymail dataset) to both models and summarize them one by one. These summaries will be used later on by our LLM judge to determine who did it better.
# Loop through articles
for i, (article, reference) in enumerate(zip(articles, references)):
print(f"\nEvaluating Example {i + 1}/{len(articles)}")
# Generate summaries
Gemini_model_sum = generate_summary(Gemini_model, article)
meta_Llama3_sum = generate_summary(meta_Llama3, article)
if not Gemini_model_sum or not meta_Llama3_sum:
print(f"Skipping example {i + 1} due to empty summary")
continue
# Print summaries
print(f"Gemini summary: {Gemini_model_sum}")
print(f"Llama3 summary: {meta_Llama3_sum}")
print(f"Reference summary: {reference}")
The output of the above code will print summaries generated by both models along with the reference summary.
Get the LLM-as-a-Judge decision
And finally, we will call the gpt_compare_summaries() to call the judge (GPT-4o in our case). If it determines that Gemini has a better output, it will vote for it; otherwise, it will vote for Llama.
#Get LLM-as-judge decision
decision = gpt_compare_summaries(article, Gemini_model_sum,meta_Llama3_sum)
if decision == "Google_Gemini":
Gemini_wins += 1
elif decision == "meta_Llama3":
llama3_wins += 1
else:
ties += 1
# Print results
print(f"Gemini wins : {Gemini_wins}")
print(f"meta_Llama3 wins : {llama3_wins}")
print(f"Ties : {ties}")
print(f"Winner (by GPT-4o): {decision}")
In the end, we will simply get an output:
===== FINAL RESULTS =====
Gemini wins : 12
meta_Llama3 wins : 34
Ties : 1
Winner (by GPT-4o) is: meta_Llama3 wins
As mentioned earlier, we can’t rely too much on a single LLM and can always try using some other LLMs (like LlaMa or Falcon) as judges, too.
How LaunchDarkly helps teams get LLM evaluation right
LaunchDarkly provides AI Configs, which help us manage prompts, models, and some parameters at runtime. It enables us to easily run experiments, observe them graphically, and collect relevant metrics.
Let’s see an example of how to use Launch Darkly’s AI Configs.
Go to Launch Darkly and create a new AI Configs project, such as 'text summarization'.
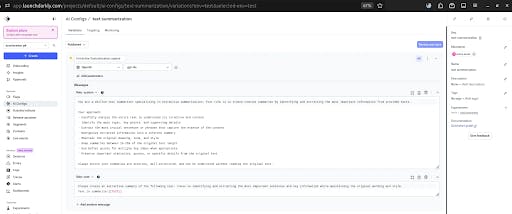
Having defined the respective prompts, we can set the test (”targeting” tab) parameters. Like a 50% split between prompt 1 and prompt 2 in our case.
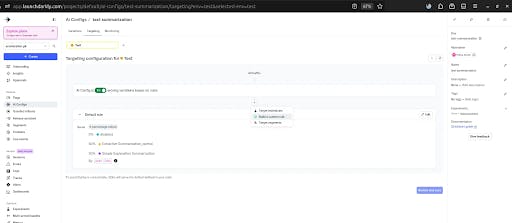
After saving the settings, we write the code to connect it with LaunchDarkly. After importing the respective libraries, set up the SDK. We would need LAUNCHDARKLY_SDK_KEY and OPENAI_API_KEY for it.
import os
import uuid
import openai
import ldclient
from ldclient import Context
from ldclient.config import Config
from ldai.client import LDAIClient, AIConfig, ModelConfig
from dotenv import load_dotenv
load_dotenv()
# Initialize the SDK
ldclient.set_config(Config(os.getenv("LAUNCHDARKLY_SDK_KEY")))
ld_ai_client = LDAIClient(ldclient.get())
openai_client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))Now we will define the generate() function. As you can see, it creates the context with user name Andy – this user is used to evaluate feature flag rules (llm_testing in our case) based on the user’s identity.
After it, we call the OpenAI API to perform text summarization and generate a response in the form of a chat conversation (both using `gpt-4o`; feel free to change the model).
def generate(**kwargs):
"""
Calls OpenAI's chat completion API to generate some text based on a prompt.
"""
user_id = str(uuid.uuid4())
context = Context.builder(user_id).kind('user').name('Andy').build()
flag_enabled = ldclient.get().variation("llm_testing", context, False)
ldclient.get().track(user_id , context)
print('SDK successfully initialized')
try:
ai_config_key = "text-summarization"
default_value = AIConfig(
enabled=True,
model=ModelConfig(name='gpt-4o'),
messages=[],
)
config_value, tracker = ld_ai_client.config(
ai_config_key,
context,
default_value,
kwargs
)
print("CONFIG VALUE: ", config_value)
print("MODEL NAME: ", model_name)
model_name = config_value.model.name
messages = [] if config_value.messages is None else config_value.messages
completion = tracker.track_openai_metrics(
lambda:
openai_client.chat.completions.create(
model=model_name,
messages=[message.to_dict() for message in messages],
)
)
response = completion.choices[0].message.content
print("Success.")
print("AI Response:", response)
return response
except Exception as e:
print(e)Test example
As an example, you can see the following passage:
test_text = """
The global shift toward renewable energy has accelerated dramatically in 2024, with
solar and wind power installations reaching record highs across multiple continents.
According to the International Energy Agency's latest report, renewable energy capacity
increased by 73% compared to the previous year, driven primarily by technological advancementces that have significantly reduced costs.
Chileads the world in renewable energy deployment,accounting for nearly 60% of all
new installations. The country added 180 gigawatts of solar capacity alone,
surpassing all previous records. Meanwhile, European nations have collectively
invested over €200 billion in green energy infrastructure.
The economic implications are substantial. Industry analysts project that renewable
energy will create approximately 4.5 million new jobs globally by 2026, while
simultaneously reducing energy costs for consumers by an average of 15-20%.
"""
result = generate(TEXT=test_text)
print(f"Result: {result}")
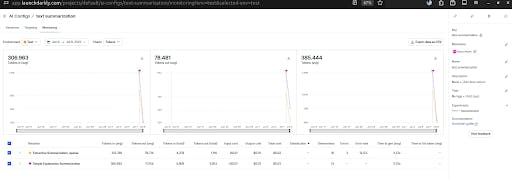
print("\n" + "=" * 50)Switching to the “Monitoring” tab, we can view relevant metrics, such as token flow and detailed statistics, including generation versus error rates.
Monitoring the text summarization using LaunchDarkly AI config.
Eight LLM evaluation best practices
The eight best practices below can help AI engineers get LLM evaluation right and avoid common mistakes.
Align LLM evaluation to real-world use
Benchmarks like MMLU are useful, but may not reflect your specific task. A model great at trivia might still fail at customer support. Always test on data close to your actual use case.
Metrics need context.
A high score doesn’t mean the model is right in ways that matter. Combine surface-level metrics with semantic checks and human review. For example, a chatbot might get the wording right but misinterpret the user’s intent.
Re-evaluate as you go
Model updates can shift performance. Test regularly after fine-tuning or retraining to catch regressions early. One good evaluation run isn't enough.
Use both general and custom tests
Tests like HELM or TruthfulQA demonstrate the general capabilities of LLMs. Teams can conduct more refined evaluations by adding domain-specific sets — such as legal clauses or customer emails — which help evaluate an LLM for specific use cases.
Balance scale and judgment
Automated scores and LLMs as a judge are scalable, but sample outputs should still be reviewed by humans. This helps catch issues with tone, clarity, and brand voice.
Avoid data leaks
If evaluation items were seen in training, the results are invalid. Keep a “surprise” set and audit for overlap, especially with popular benchmarks.
Track quality and efficiency
High accuracy isn’t enough if latency triples or costs spike. Log token counts, p95 latency, and dollars per 1K tokens to monitor real-world performance.
Monitor LLM performance in production
Deploy continuous checks on live traffic. If quality drops or latency climbs, alert and investigate — don't wait for users to complain.
Conclusion
The widespread use of LLMs, particularly in critical applications, makes their evaluation a crucial topic. Evaluating LLMs is important but quite challenging due to issues such as benchmark limitations, the cost of human feedback, and bias. We have seen the challenges associated with and attempts to mitigate them. LaunchDarkly provides us with AI Configs, which can be quite useful in LLM evaluation, especially when using LLM as a judge. The practical examples invite you to replicate them and/or apply them to your problem domain. As LLM evaluation is a rapidly evolving domain, AI engineers should stay informed about the latest research and continually evaluate the effectiveness of their models using various evaluation techniques.