





Can you trust your experiment results? This can be a critical question when you’re deciding which feature variation to ship. If you can’t trust your results, there’s no point in running an experiment.
Unfortunately, many experiments appear valid at first, until your data science team digs a little deeper. In these cases, the problem is usually the composition of your sample.
When randomness works against you
In a randomized experiment, you assume traffic is split fairly between variations, meaning that groups are “equal enough.” But that’s not always the case, especially in small sample sizes or B2B environments.
This is called covariate imbalance: when baseline characteristics (covariates) such as user size, region, or device type are not evenly distributed between the control and treatment groups. That imbalance can bias results by confounding the true effect of the tested feature.
Let’s break it down with an example.
Say you’re an e-commerce platform for B2B companies. Most of your customers (90%) are small businesses, but a few large enterprise customers (10%) account for a significant share of revenue. You want to test a new checkout flow, and your goal is to increase the average purchase total.
You run an experiment and randomly split users into two groups:
- Control: sees the old checkout
- Treatment: sees the new flow
But by random chance:
- The control group ends up including 5 of your biggest customers
- The treatment group includes none of them
Even if the new checkout works just as well, you’ll see:
- Control group average revenue: high
- Treatment group average revenue: much lower
So the data says: “New checkout is worse!”
But that’s not true. The issue isn’t the feature; it’s that the user groups weren’t balanced. That’s covariate imbalance: it skews your outcome before the test even starts.
Stratified sampling makes your sample work harder
Stratified sampling is a re-randomization technique that helps address this problem by ensuring that important user attributes, such as company size, geography, or device type, are evenly distributed across groups.
It works by using metadata you already have to:
- Define what “balanced” means (your covariate)
- Evaluate candidate randomizations
- Pick the one that’s most balanced
In short, it prevents bad luck from breaking your test.
When should I use stratified sampling?
Here are some indicators that stratified sampling will help:
- Your user base is small or skewed
- Certain attributes (like spend, region, or behavior) have a disproportionate impact on metrics
- You need more confidence in your results before rollout
Setting up stratified sampling in LaunchDarkly
Here’s how to get started with stratified sampling:
- Gather a list of your intended audience, including unique IDs and the value you will use to organize them.
Pro Tip: The method performs better when there are ≤2 covariate values. Supply as many contexts (and covariate values) as reasonable. - Format your list into a CSV file.
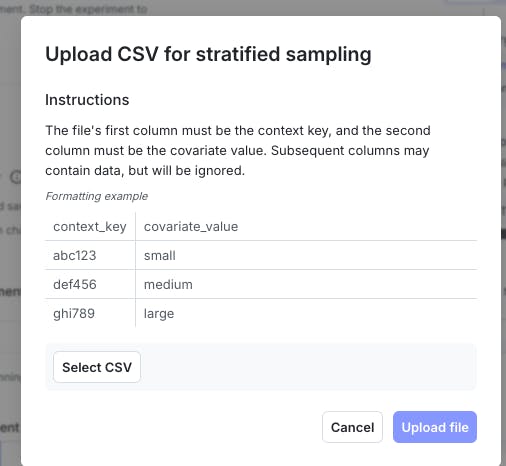
- When designing your experiment, indicate that you will use stratified sampling and upload your CSV file.
- Start your experiment after you've completed the rest of the experiment design choices.
LaunchDarkly will assign experiment traffic based on the values in the CSV. For full details, visit our Stratified Sampling documentation
Keep in mind that:
- Re-randomization applies only to known users (contexts) at the time of test creation.
- If you're experimenting with new or unknown users (e.g., anonymous sessions), stratified sampling won’t apply to them, but that’s okay. Your test will still run, just without the added balancing.
Better tests lead to better decisions
Stratified sampling helps you eliminate covariate imbalance as a variable, so you’re not second-guessing your data. That means faster iteration, fewer false reads, and smarter shipping. Try stratified sampling in your next experiment or check it out in our sandbox today.
Like what you read?
Get a demo