Control the end-to-end AI lifecycle.
Run evaluations, monitor behavior, and fix issues instantly, without redeploys.






Validate changes safely.
Evaluate offline, then prove with holdouts, shadow traffic, and pass/fail rules before you scale.

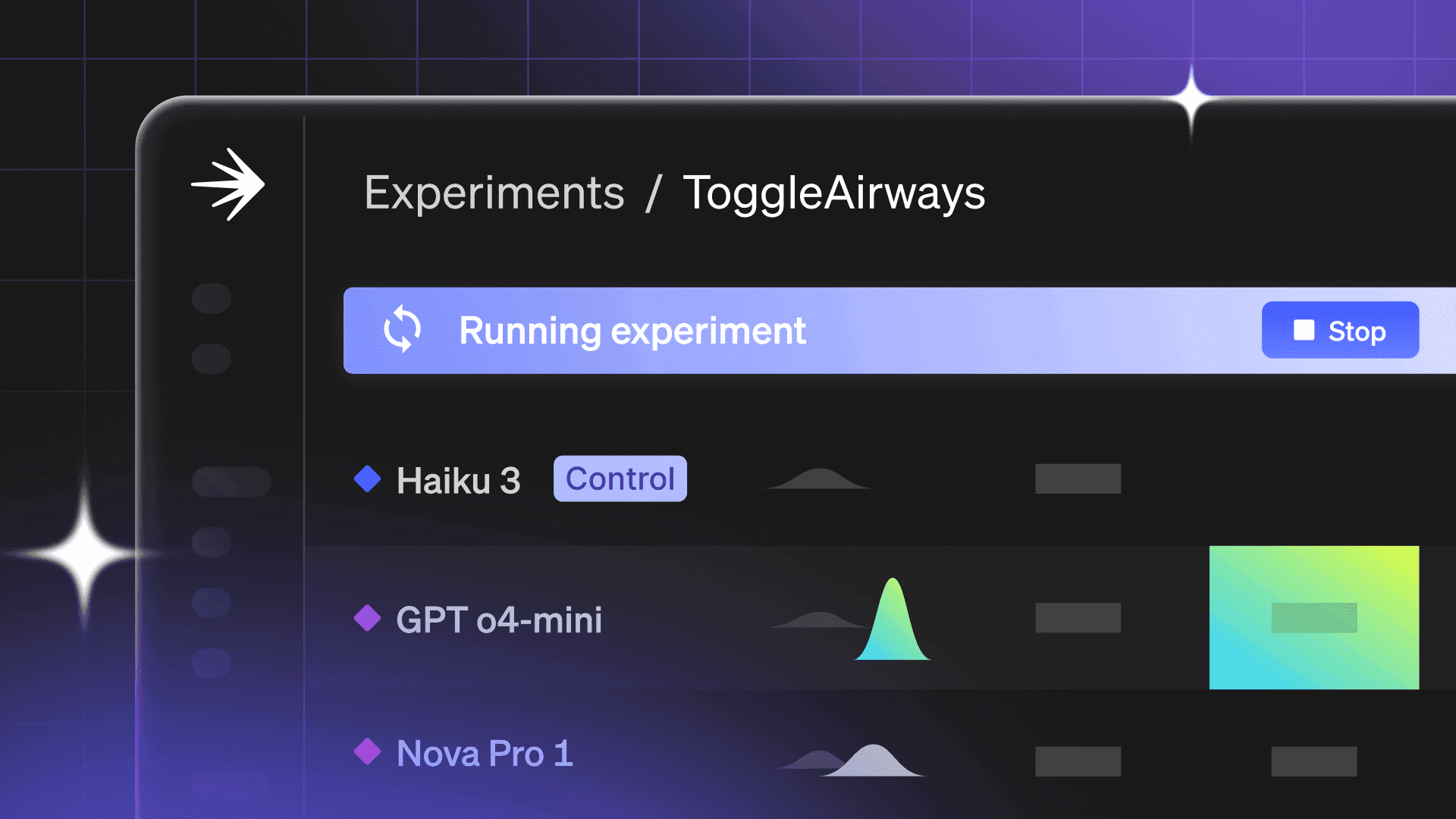
Spot regressions fast.
Detect quality or behavior changes with judge scores and traces, see exactly what changed, and get actionable alerts.

Fix without redeploys.
Restore the last known good variation or redirect traffic in seconds – no code push required.
Validate changes safely.
Evaluate offline, then prove with real traffic. Scale only what works.
Validate changes safely.
Evaluate offline, then prove with real traffic. Scale only what works.
Start in a sandbox.
Use offline evals to pre-vet changes before production checks.
Compare with real traffic.
Run holdouts, shadow tests, or targeted rollouts with LLM-aware observability to validate under live conditions.
Promote with confidence.
Use quality, latency, and cost thresholds to decide when to scale up or roll back.








Spot regressions fast.
Track how quality shifts over time, trace what changed between versions, and know exactly when to take action.
Spot regressions fast.
Track how quality shifts over time, trace what changed between versions, and know exactly when to take action.
Track the right metrics and thresholds.
Judge scores, latency, tokens, and cost per configuration or version.
Pinpoint the cause.
Follow completions, tool calls, and prompt flows; compare versions to see which change triggered the shift.
Alerts you can act on.
Get notified on thresholds and choose to pause exposure, investigate deeper, or roll back instantly.






Fix it without redeploys.
Restore a healthy state or reroute traffic fast: no code push required.
Fix it without redeploys.
Restore a healthy state or reroute traffic fast: no code push required.
Restore from last known good.
Roll back immediately to the most recent healthy variation.
Identify what works best.
Use targeting rules and guardrails to find the right model or configuration for quality, speed, and cost.
Edit safely at runtime.
Update prompts, parameters, or models with approvals and an audit trail.






Relay Network ships secure genAI capabilities for regulated clients with AI Configs.
/ /
I think what I’m most proud of is how quickly we brought everything together and got it in people’s hands, with all the monitoring and feedback in place so we could actually see what was happening.
Read more

Poka goes “flag-first” to transform its release processes and AI innovation.
/ /
If prompts were only on the backend, only the backend people could modify them. But since they're a flag in LaunchDarkly, the product managers, front-end developers, or even the designers might have access to modifying them if they want to test something out.
Read more




Learn more about AI Configs.

DEMO
Move at AI speed. Stay in control at runtime.
Watch how LaunchDarkly gives you runtime control after deploy — so you can release safely.

Blog
Understanding AI behavior: LLM observability in AI Configs
Get deeper visibility into model behavior and impact with LLM observability.
Blog
Online evals: LLM-as-a-Judge
Online evals in AI Configs give teams quality signals to successfully ship AI changes.

Blog
Introducing AI Experiments and AI Versioning
Test, optimize, and manage AI Configs to accelerate AI app development

Blog
Prompt versioning & management guide for building AI features
Learn how prompt versioning can help you maintain consistency across your applications.

Blog
AI model deployment: Best practices for production environments
A developer's guide to deploying ML models using LaunchDarkly AI Configs.









Evaluate, observe, and improve your AI lifecycle – without redeploys.
