





A monolith is a software application with multiple features and responsibilities intertwined. Regardless of the application’s overall performance, its growth is correlated with its capacity to evolve quickly. Monoliths are highly coupled, and maintaining this kind of application involves many challenges, thus creating an appeal for many to migrate to a more manageable setup.
Microservice architecture is a great choice for decoupling monolith applications. It provides significant improvements for your application’s maintenance, deployment, and scalability. If you face application challenges that prevent you from introducing new features, upgrading new ones, or releasing updates often, you may want to make the change from a monolithic approach toward microservices.
Feature flags, container orchestration, and monolith migration patterns are a few strategies that you can employ to ease the transition. Feature flags, often called toggles or switches, are a mechanism that allows you to manage an application feature by limiting its visibility and behavior. In practice, you can use them to test and deliver new features in your application.
Container orchestration involves the automation of several processes in the management, scalability, and observability of container workloads. A container orchestration platform can perform automatic tasks, such as provisioning, instantiating, and scaling. By containerizing your microservice logic, you separate things into manageable parts that can be independently released from the original application.
Finally, monolith migration patterns are frequently used to solve specific problems using tested strategies. In this guide, you’ll learn what some of them are and how they interact in hypothetical scenarios. You’ll also learn more about feature flags, container orchestration, and other useful tools to employ in a monolith migration.
Using container orchestration and feature flags
While container orchestration alleviates the pain of managing container workloads, feature flags accelerate development cycles, providing a safer way to isolate and release new functionality. Container orchestration and feature flags make up the perfect duo for a variety of cases. Here are some examples:
Agile planning: Agile is a software methodology that promotes the release of incremental additions to a product. With agile planning, software teams all over the world have gained access to better tools to plan and deliver great products. Features flags and container orchestration are part of these tools, and when combined with agile planning, they allow product and engineering teams to test and experiment with new features more frequently by decoupling releases from deployments.
Decoupling of monoliths: Decoupling a monolith into microservices facilitates the maintenance of existing features and the development of new ones. These microservices can adopt feature flagging to control their execution, response, and even general availability so the monolith can keep communicating with them as if they were never decoupled.
Scalability: If the reason you are considering breaking apart your monolith is to enable independent feature growth, then the isolation and containerization of your feature will help you succeed in this endeavor. Once your feature has been detached, it will present new opportunities. Without the boundaries of its previous host, your microservice can scale independently. You can set up a new custom configuration for the microservice with container orchestration. For instance, you might want to limit the number of replicas of your microservice to one or two for the development environment but allow a higher number in a production environment. You could also consider introducing a feature flag for this number, allowing you to easily control how many replicas you want for a specific environment.
Observability: In software, observability refers to the ability to estimate a system’s state by looking at its properties and outputs. Container orchestration platforms prioritize observability, giving you full visibility into the health of your microservices.

Learning how to migrate monoliths to microservices
Monoliths are appropriately named because they are large pieces of software with features that have been added across a span of time; it’s highly likely that some of those features were not considered during the original draft of the system.
If you want to break apart those features into isolated modules—microservices—you’ll probably need to use a few different strategies. Let’s take a look at how agile planning, software patterns, and container orchestration can help in your migration.
Using agile planning
When breaking apart a monolith, you need to make sure you move cautiously and steadily. The first functionality (feature) you pull out from your monolith may not be the target feature you are most interested in. You might start by moving one of its surrounding connections first and, eventually, reach a level of confidence to move more system-important features. Prioritizing features and detecting feature dependencies and relationships with the rest of the application using agile planning will help estimate the overall effort required to transform the features into microservices as well as the order in which each step needs to occur.
The order of these releases can be tracked using release planning, which involves a live document that defines how and when releases will happen. Furthermore, feature flags allow you to deploy functionality and keep it hidden until it’s ready to be used. When you combine feature flags and release planning, you gain a granular level of visibility on your overall system, allowing you to anticipate upcoming migrations and release more confidently and with less risk.
Again, features don’t have to be complete in order to be deployed; they just need to provide incremental enhancement toward the goals you’re aiming for. This is a fundamental difference between deployment and release. You can ship and deploy features often while protecting the widespread visibility of certain functionalities until they’ve been fully tested and are able to be released with confidence. By deploying early and often, you can choose whom to show your upcoming features before perfecting and revealing them publicly. Thus, best practices dictate that you deploy features regularly as part of your development phase.
Applying software patterns
In this following section, you’ll learn about several software patterns commonly used during a monolith migration. Before diving in, consider a hypothetical scenario that will be used to illustrate the patterns in action.
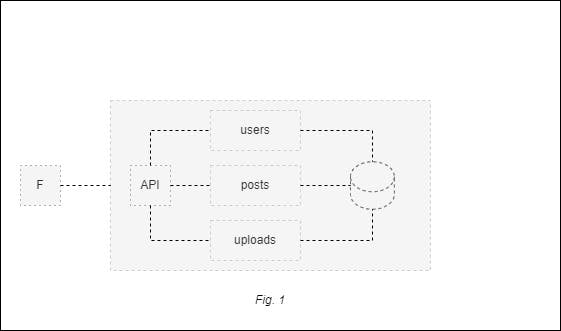
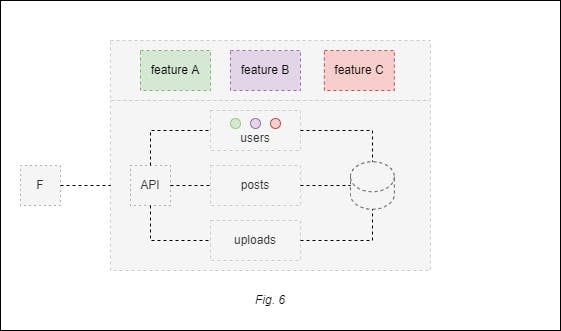
Scenario: Consider a monolith application consisting of three previously identified modules (users, posts, and uploads) with a single database. The users module contains the authentication and authorization fields. The posts module allows a user of the application to create, edit, and remove posts, which may contain media attachments. Finally, the uploads module allows the user to upload a photo or video directly into the application server. Figure 1 below demonstrates this setup.
In this scenario, it’s been decided that new features will be added to the application, including the adoption of new technology. The team has identified third-party APIs to leverage each of the existing functionalities, so before adding the new features, the monolith will be split into microservices.
Now, let’s take a look at some migration patterns.
1. Strangler fig pattern
This pattern is named after a type of vine that grows around trees. In a strangler fig pattern, you’re looking to extract legacy functionality or add a new functionality outside of the monolith system in an incremental fashion.
You would want to use this pattern, for example, to extract the users module outside of the host application (monolith) in a microservice, as demonstrated in figure 2 below. The implementation of this microservice can contain its own logic for authorization and authentication.
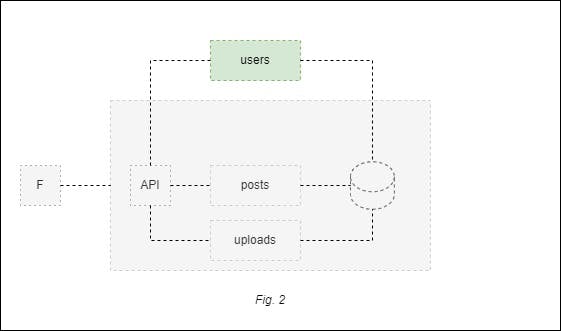
As Martin Fowler explains, in a strangler fig pattern, “an alternative route is to gradually create a new system around the edges of the old, letting it grow slowly over several years until the old system is strangled.” By creating a users microservice, you’re also effectively creating a new system outside of the monolith that will eventually replace (strangle) the users module inside the monolith.
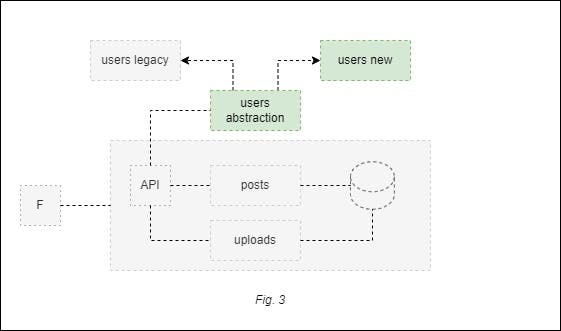
2. Branch by abstraction pattern
The primary goal with this pattern is to abstract, encapsulate, and isolate a functionality. You might choose this pattern if you’re still on the fence about the implementation details. For instance, you might want to implement Amazon Cognito for authentication, but you also find the possibility of using Auth0 very compelling. By abstracting and encapsulating this module functionality, you force implementations to adhere to the same requirements, so you can seamlessly use either implementation.
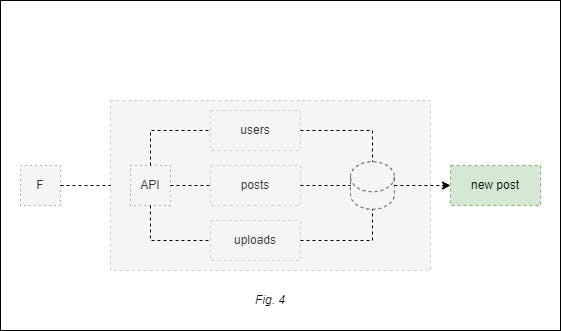
3. Change data capture pattern
This pattern’s primary goal is notifying changes in the database for another process to keep its own version of that data.
You would use this pattern when you expect modifications in your data. It could be that you know that the input data will change or that additional transformations down the road will be required, as these kinds of improvements can’t occur on a live system.
Taking our hypothetical scenario as an example, you could use the data capture pattern to make a copy of every post created in your application and prepare this data for later consumption.
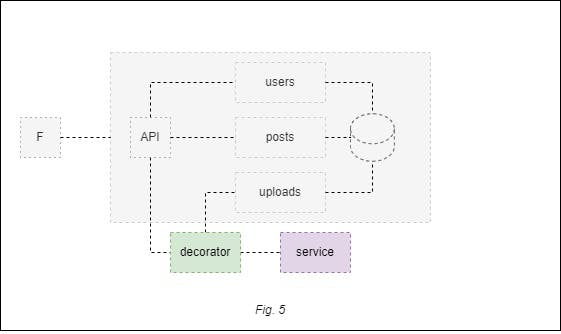
4. Decorating collaborator pattern
This pattern introduces a layer in front of the feature you want to change. The layer will perform two invocations: one to the legacy feature and another to the replacement service.
In our hypothetical scenario, you could separate the uploads module from the monolith and use an external API to store user file uploads.
This software pattern guarantees system integrity while allowing you to extend its functionality.
Using feature flags and release planning
You might find it difficult to put your finger on the right pattern for your migration endeavors, and sometimes, using two patterns may be the appropriate solution for your situation. While this may be permissible, the implementation details may favor one pattern over the other in terms of the benefits, resources, time, and effort required. In this case, you can leverage a feature flag mechanism to show the path that a request must follow based on the context of the request. This way, you can easily validate new features with experiments, whether locally or in a more production-like environment.
Also, as mentioned previously, release planning allows you to estimate the release date of any given feature. When feature flags and release planning are used together, it becomes easier not only to release new features but also to roll back in case something doesn’t come out as expected. For more, check out our article, "Using Feature Flags to Avoid Downtime During Migrations."
Deploying using container orchestration
Once your feature has been prioritized, isolated, and containerized, the next step is to deploy it so your application can call it as if it never left the monolith. There are some considerations to keep in mind, though. Let’s take a look at a few.
Service discovery
According to Wikipedia, service discovery is the process of automatically detecting services on a computer network. When you deploy your microservice and it becomes network available, a container orchestration platform takes its IP addresses and saves them for future reference. Multiple IP addresses would be stored if multiple copies of your microservice were required.
Because microservices can scale up and down, you wouldn’t rely on a specific IP address as the definitive address to be used in the rest of your application. Rather, you’ll leverage a container orchestration platform to provide an address that doesn’t change, regardless of the number of microservices copies. These addresses are DNS values that resolve to a specific IP address.
In practice, your application will use DNS values whenever it tries to communicate with your microservices.
Scalability
With your feature now deployed, you don’t want to have to worry about its performance or host capabilities, such as RAM, CPU, and disk space. Thus, you can leverage container orchestration to automate scalability tasks to allow your service to scale on demand automatically. This is especially handy if your microservice outgrows its expected usage and needs to scale without manual intervention.
Container orchestration platforms also allow you to set the minimum and maximum replicas allowed for your microservice.
Self-testing
The capacity to detect and expose one or several metrics that can serve as a general service status is called self-testing.
A container orchestration platform can infer microservices health based on their outputs or a self-testing metric. One of the orchestration platform’s jobs is to constantly monitor the microservice’s health and mark it as available or unavailable. Unavailable nodes often cannot accept incoming traffic or communication from the outside.
Self-testing helps your application identify and react in situations with unavailable microservices.
Conclusion
In this article, you learned about how feature flags, agile planning, monolith migration patterns, and container orchestration can help you plan your migration from monolith to microservices with confidence.
If you're wanting to learn more about how LaunchDarkly can help with migrations, check out the video below from a talk we gave at AWS re:Invent 2021.
Like what you read?
Get a demo