





The rapid evolution of LLMs and GenAI has opened up a world of possibilities for software teams across industries. The applications are vast and transformative, from enhancing customer service with intelligent chatbots to automating content generation. However, bringing non-deterministic AI applications to production at an enterprise scale presents a set of unique challenges.
We asked hundreds of software engineers what was holding them back from accelerating new GenAI releases for their core products, and the most common challenges were:
- Tooling for managing hundreds of prompts in code: Crafting and managing the right prompts is crucial for getting reliable outcomes from LLMs. Should your AI assistant be "friendly and helpful," "reliable and helpful," or "reliable and polite?" The subtleties in prompt wording can significantly affect the AI's responses, making prompt engineering a critical but often cumbersome task that requires managing, testing, and deploying hundreds of versions.
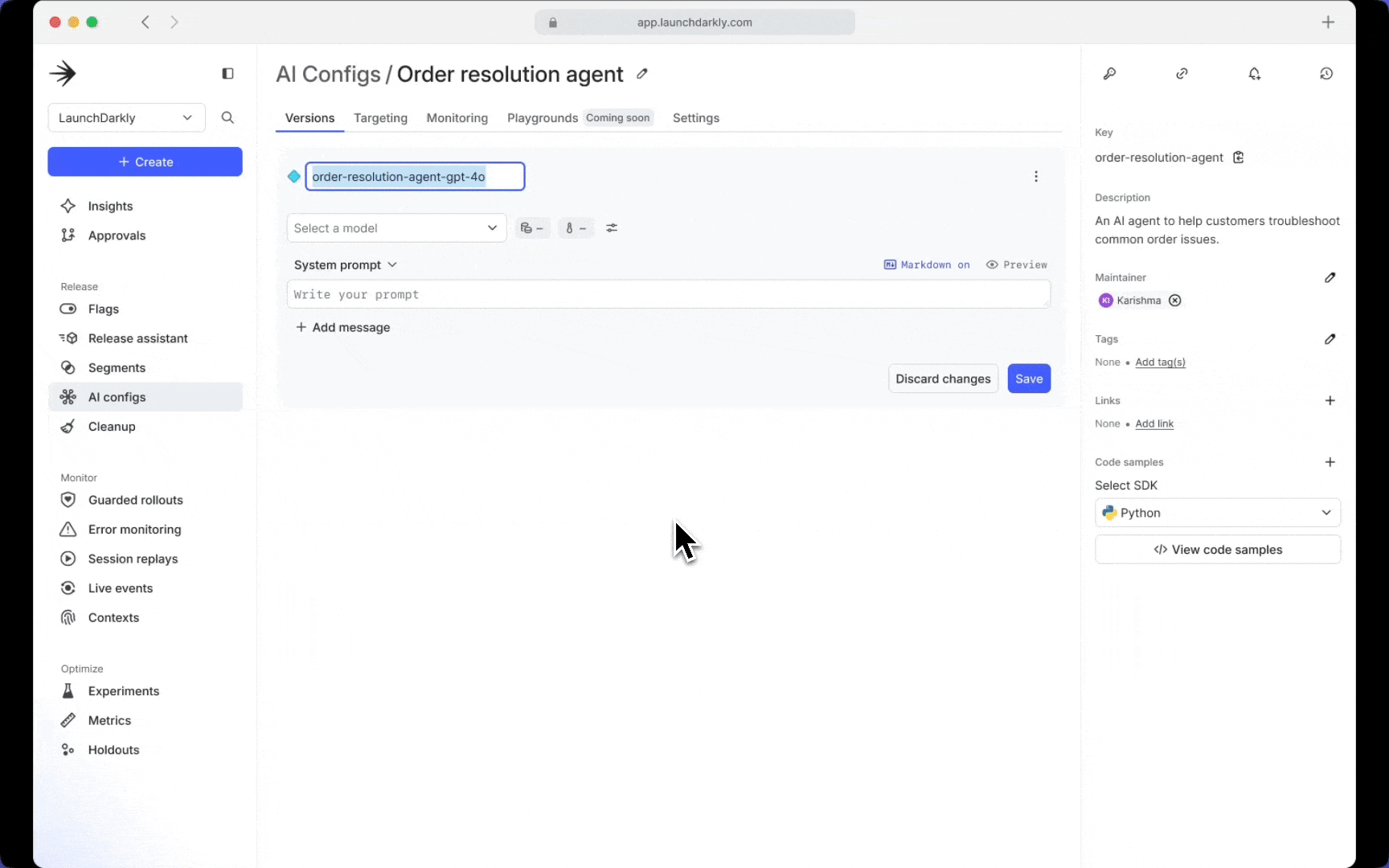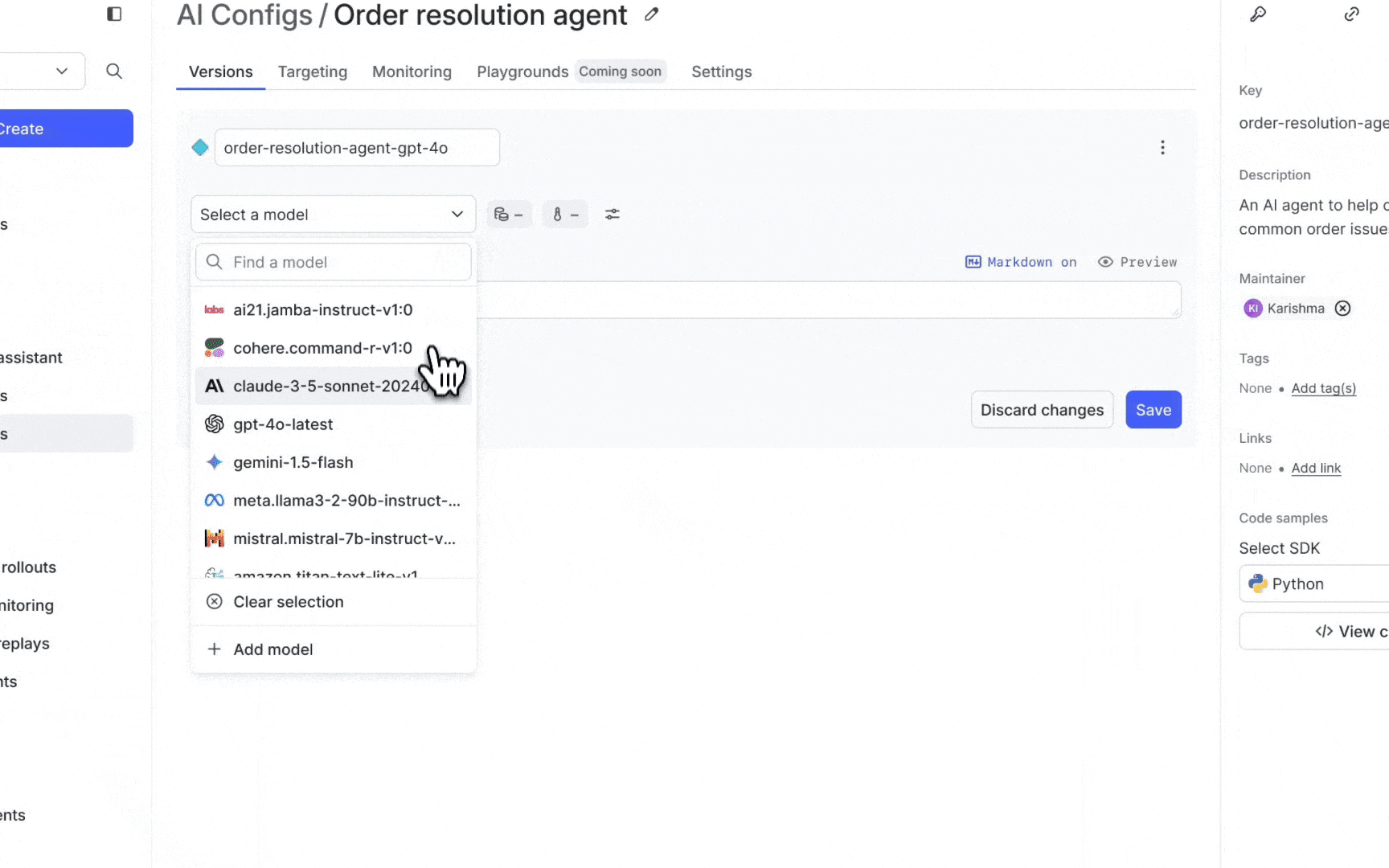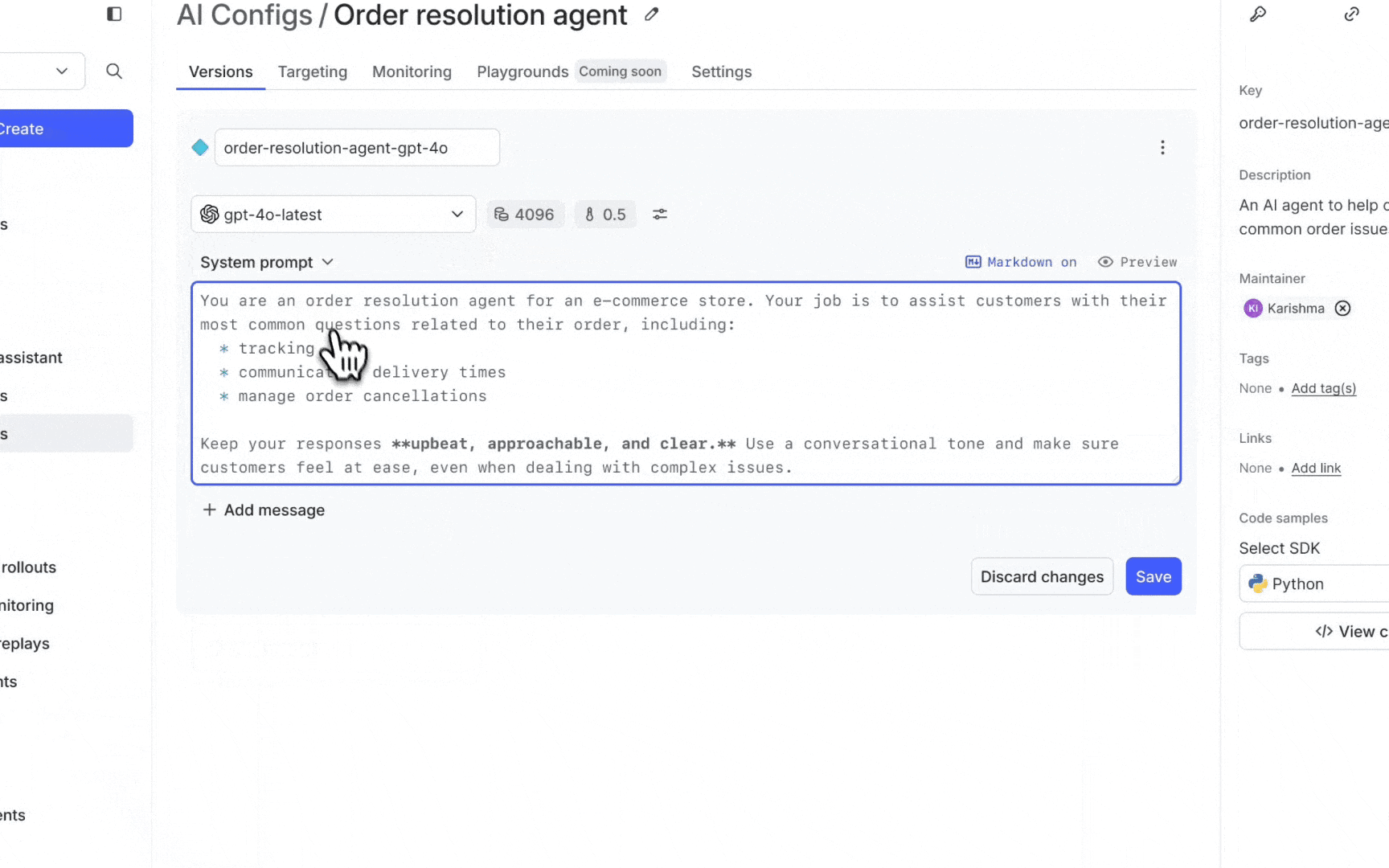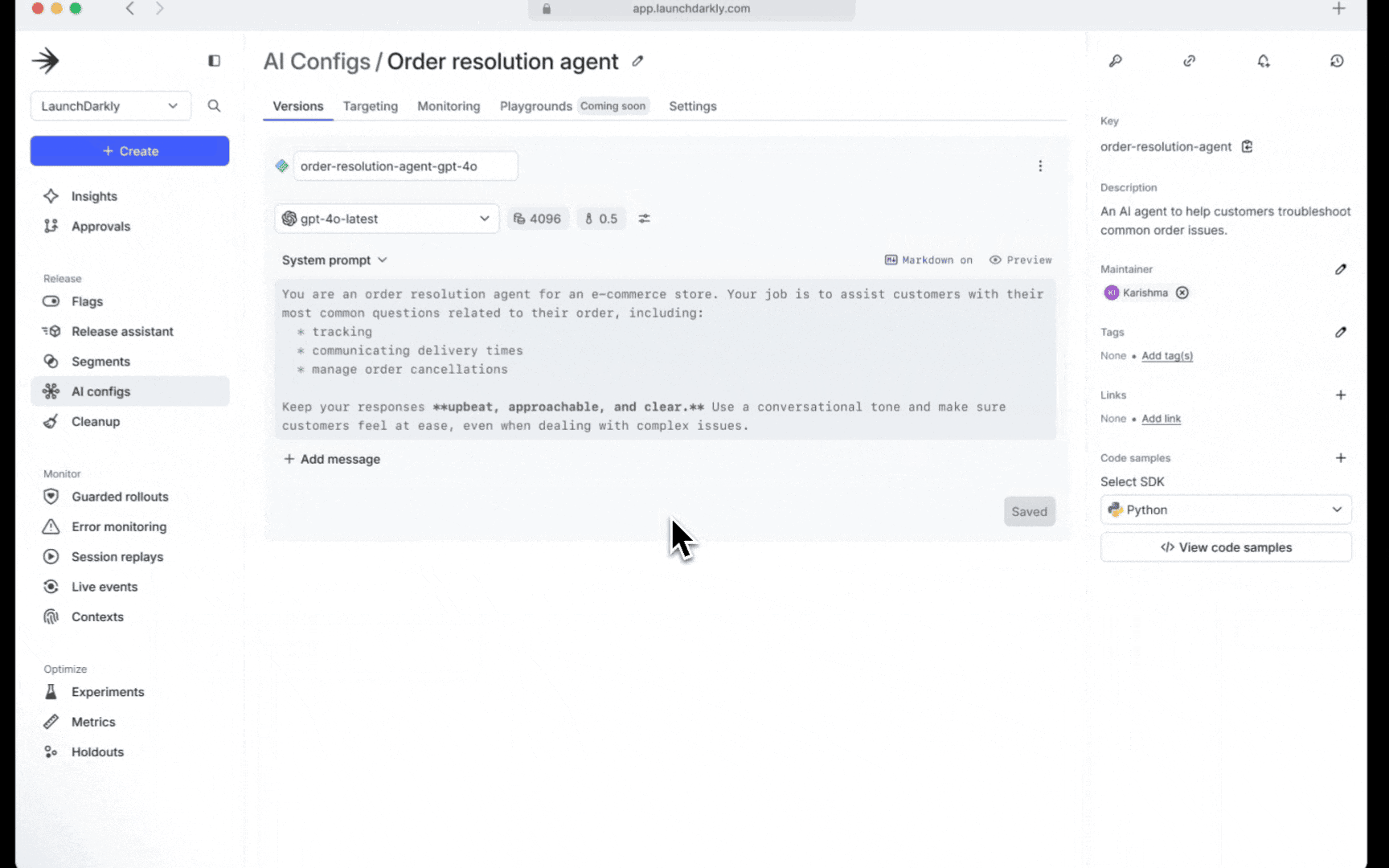
- Rapid pace of new models: New models and techniques emerge so frequently that teams can struggle to determine the optimal model configuration and prompt combination before the next advancement arrives. This constant flux can make it challenging to settle on a solution that performs reliably at scale.
- Inability to measure the impact of changes: While existing observability dashboards can give some insight into the overall performance of the application’s health, GenAI development introduces the need for monitoring additional metrics such as the cost related to token usage and output satisfaction rate of your model’s responses. Not having an easy way to monitor these metrics makes it difficult to confidently report on the user and business impact.
- Unknown risk of non-deterministic models: Not all new models are categorically better than their predecessors. While a newer LLM might be more effective by most measures, it can have weaknesses that impact specific use cases. Teams should thoroughly test and understand these nuances, adding another layer of complexity to the development process. Because AI is non-deterministic, there’s also more inherent risk for the end-user experience. In other words, when things go wrong, they can go really wrong, in a way that negatively impacts your public perception and bottom line.
At LaunchDarkly, we've always been committed to helping developers de-risk their software releases, which is why we're thrilled to introduce AI Configs – to extend the value of feature management to engineering teams building GenAI software and help them with the challenges that come with it.
AI Configs: The modern tool for managing your GenAI products at runtime
LaunchDarkly can help your team manage, test, release, and monitor your next GenAI feature, without the need for complex and non-scalable config files or additional tooling. With access to LaunchDarkly’s AI Configs, your team can:
- Create and manage prompt and model configs (AI configs) at runtime
- Instantly roll back to a stable configuration in case of issues
- Visualize and monitor for regressions on key metrics like token usage for confidence
- Target AI Configs to various audiences to customize the end-user experience
- Run multiple configurations against the same application to track performance changes
Let’s take a look at how some of these work in the product.
Runtime management of prompts and models
Easy runtime management empowers teams to adopt new models almost instantly and update parameters without the need for redeployment to test them out. This flexibility also allows for rapid iteration with prompts to continually refine and improve the end-user experience. Runtime control also means that in case an issue occurs, you can immediately disable the problematic version and revert to a stable configuration without any disruption to the end users’ experience.
Visualize and monitor key metrics
LaunchDarkly’s AI-native SDKs make it easy to track key metrics such as token usage, allowing teams to gain real-time insights and swiftly identify any regressions. With these metrics, you can monitor each update to your GenAI feature and gain a clear understanding of how changes to prompts and models are impacting performance, user satisfaction, and cost.
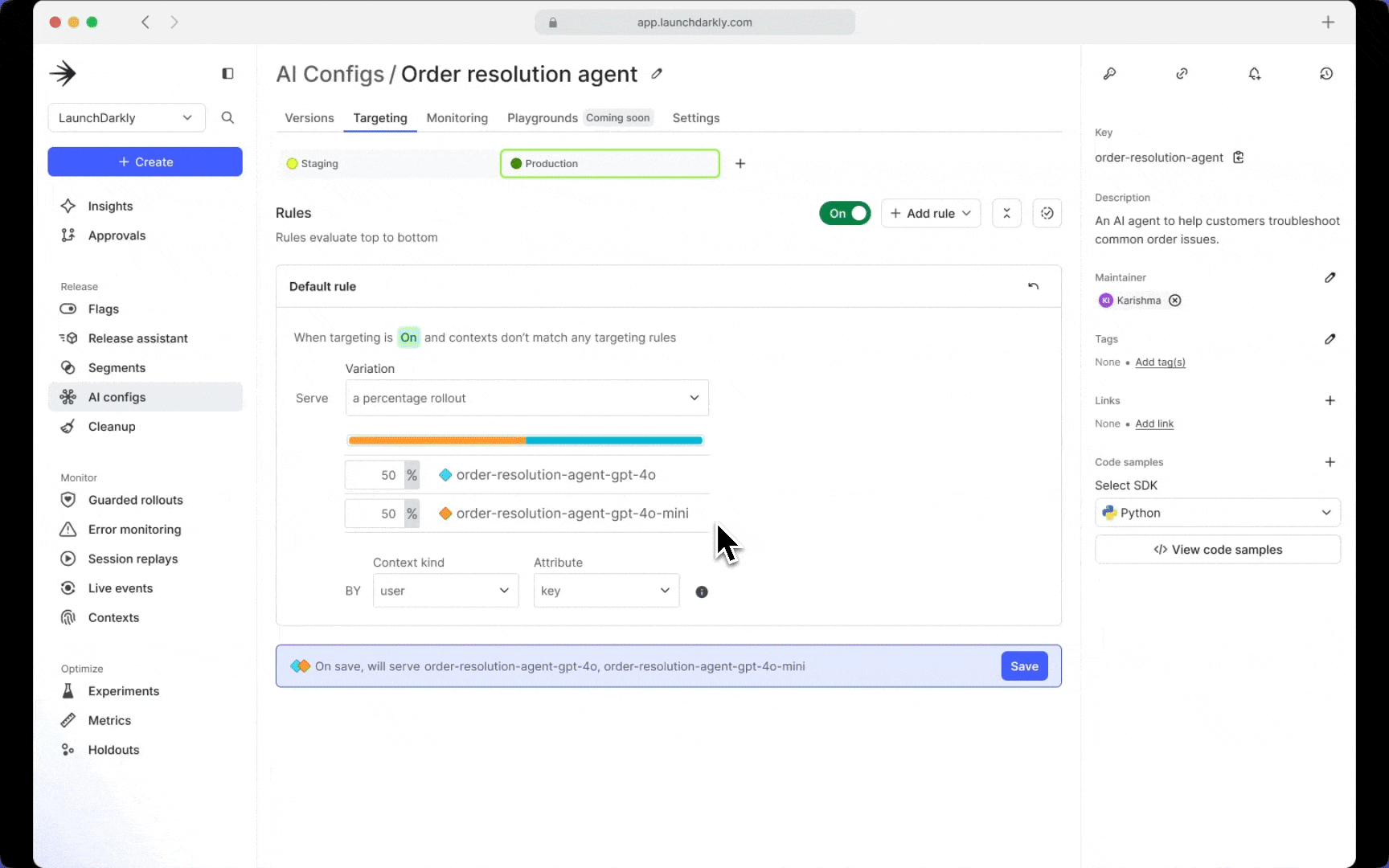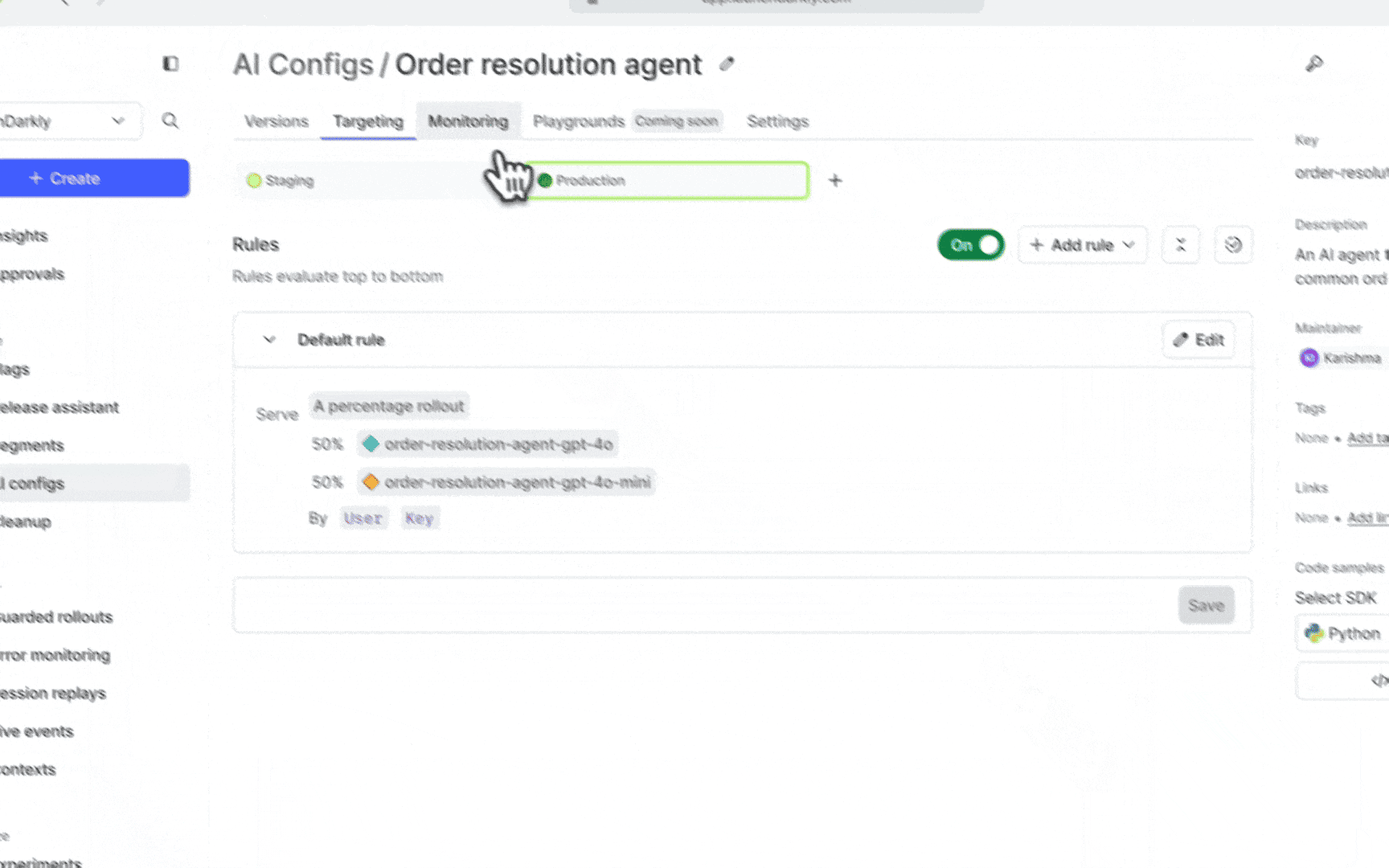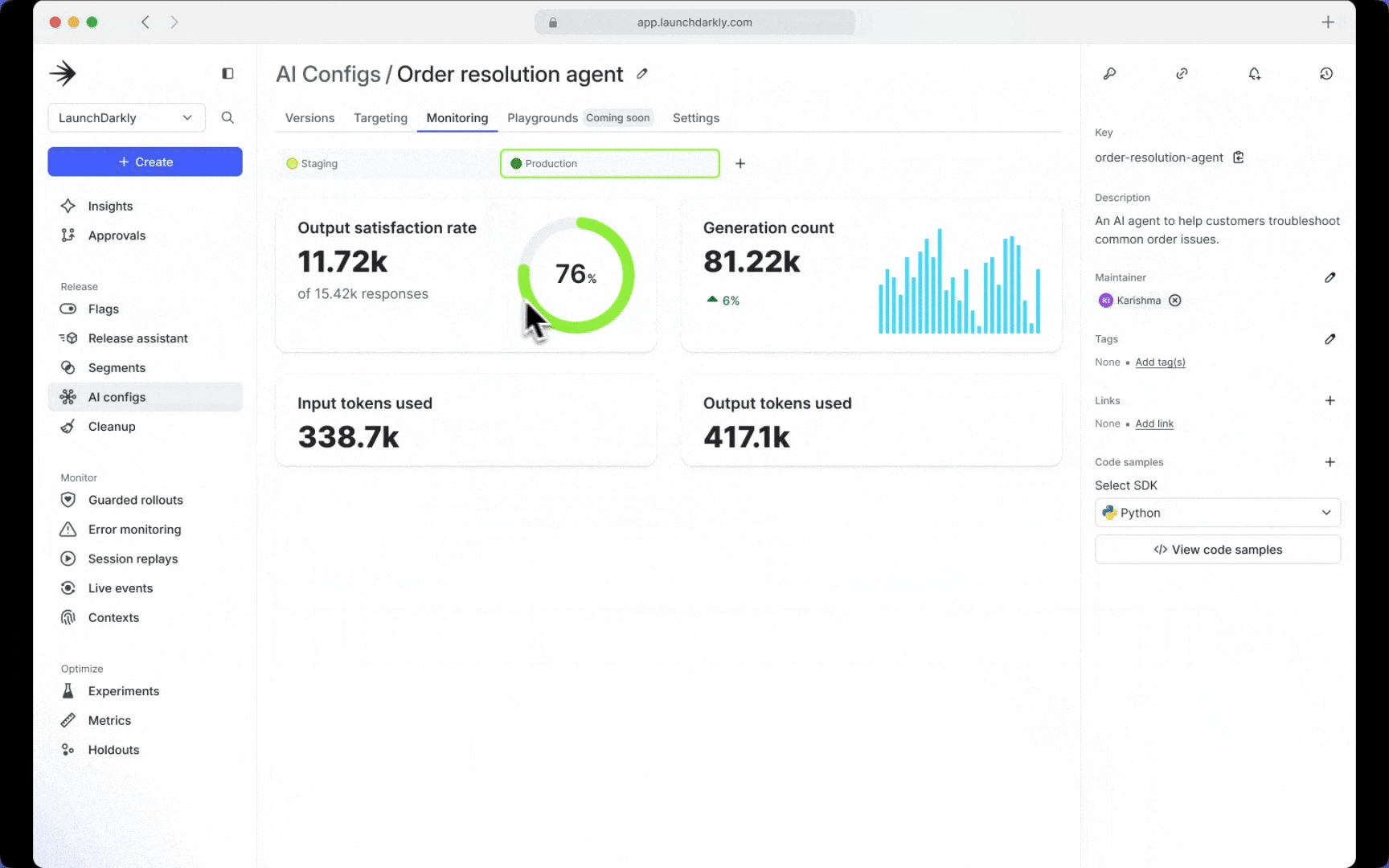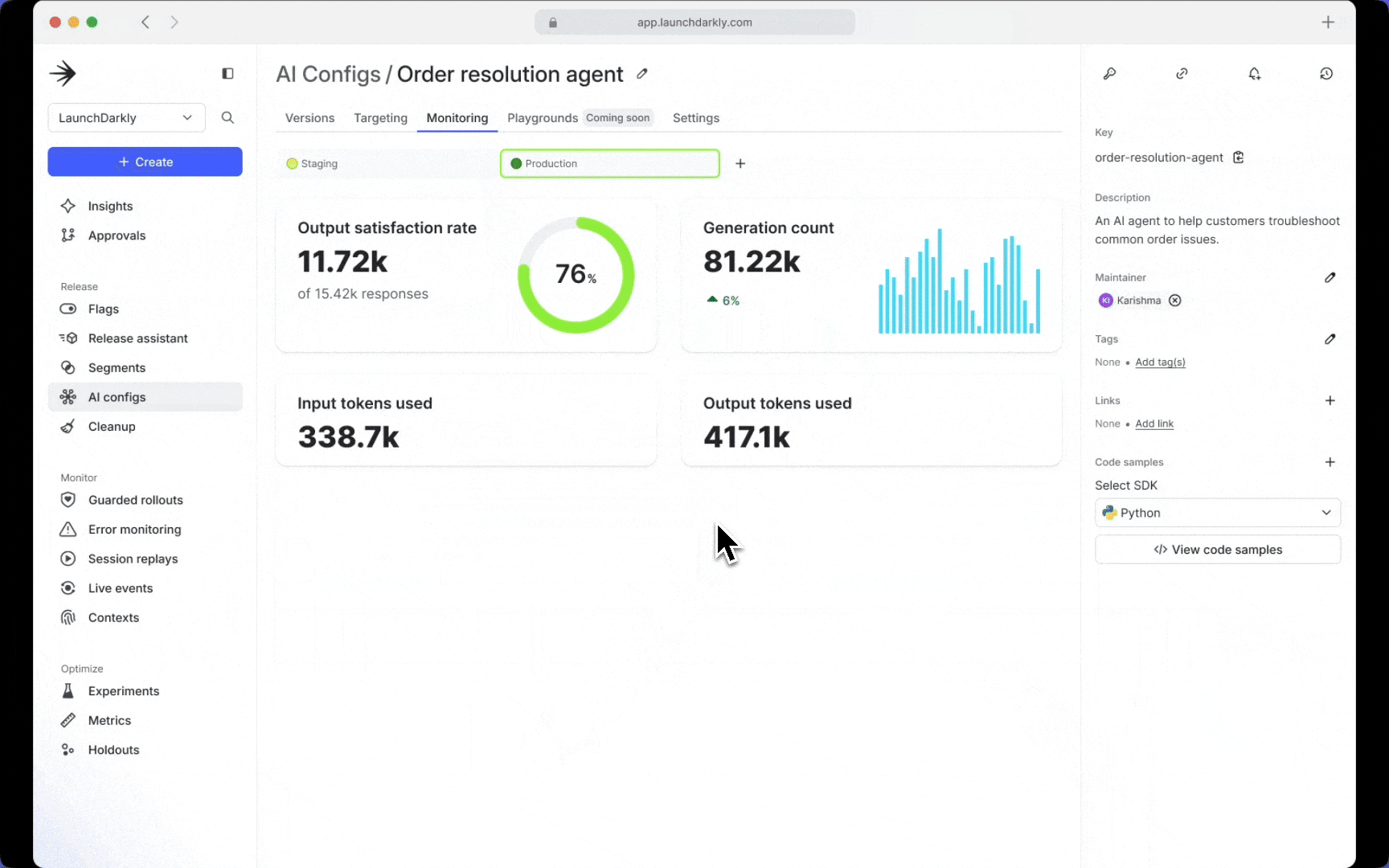
Target and customize AI experiences
When rolling out a new model version or prompt iteration, the best practice is to do so by exposing it to a small set of users first to make sure that it works as expected. The ability to target different versions of your AI Configs to specific user segments allows for tailored experiences and controlled rollouts. By gating access to larger, more resource-intensive models, teams can also manage expenses effectively while delivering advanced capabilities to targeted audiences.

Get started with AI Configs
Are you ready to accelerate your team’s GenAI development and bring safer, more reliable AI features to your users?
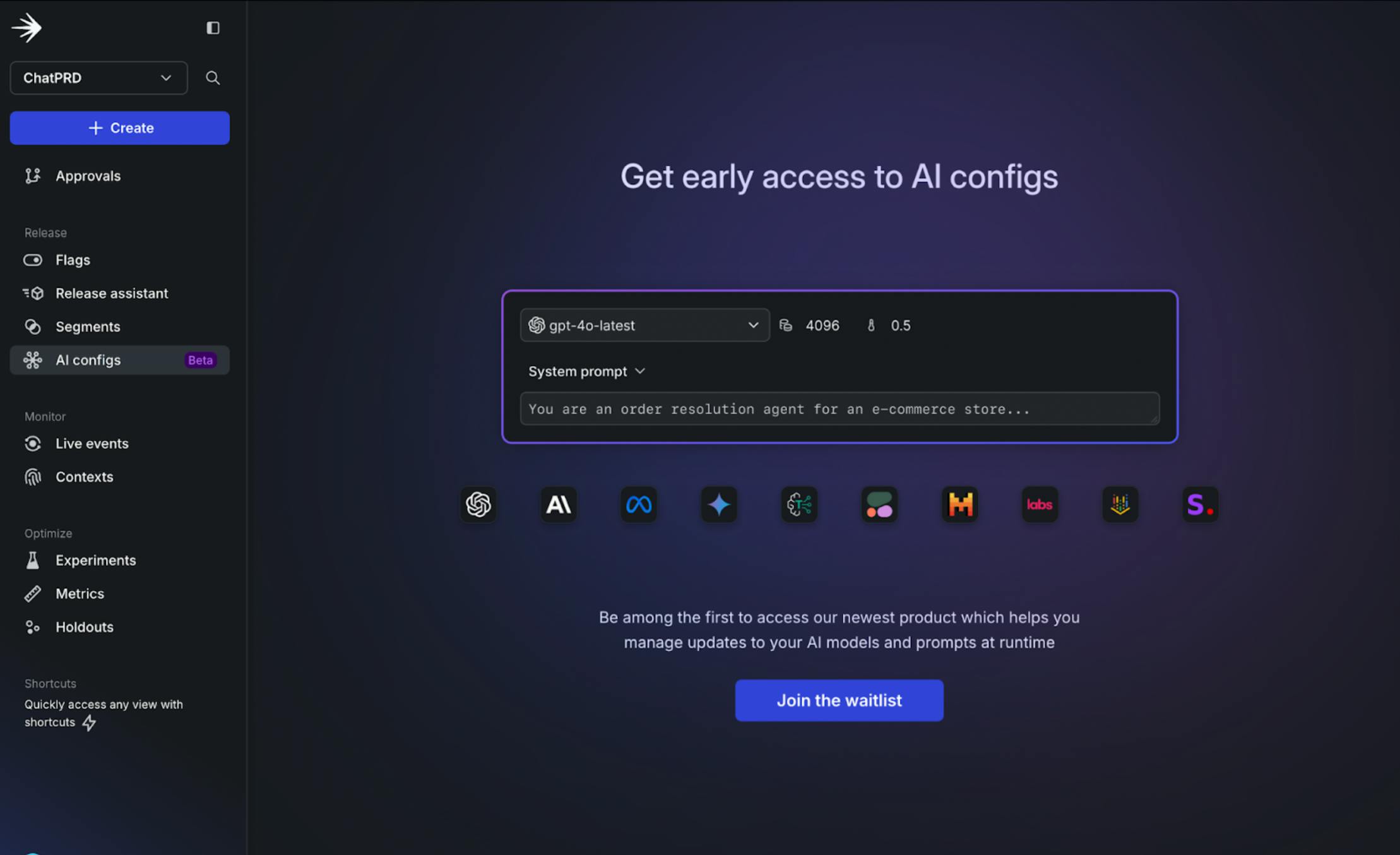
To request early access, simply go to the ‘AI Configs’ menu in LaunchDarkly or email product@launchdarkly.com with any questions. Thanks for reading!
Like what you read?
Get a demo